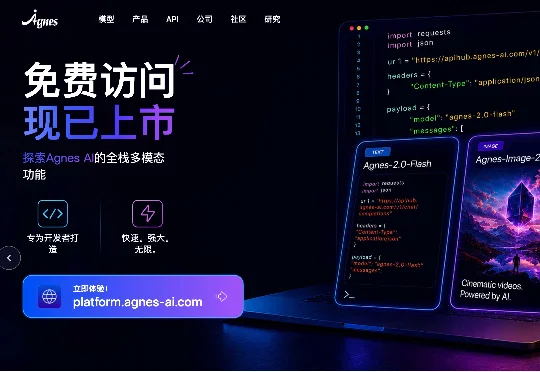
AI实验室Agnes AI开放全模态不限时免费API!重点是免费!
AI实验室Agnes AI开放全模态不限时免费API!重点是免费!在这场日益蔓延的“Token焦虑”中,Agnes AI的举动显得格外扎眼——这家全球榜单排名第九的AI Lab宣布,自6月1日起,旗下全模态模型API无限期免费开放。Agnes AI本次开放覆盖其三款核心模型:文本模型Agnes-2.0-Flash、图像模型Agnes-Image-2.0-Flash以及视频模型Agnes-Video-V2.0。
来自主题: AI资讯
11736 点击 2026-06-01 11:24